Einleitung
Wir richten ein zentrales Git Repository, sowie eine Maven Repository Management Software zur Verwaltung eines zentralen Repository bzw. als Proxy zwischen allgemeinen Maven remote repositories.
Anschließend werden wir die Client Installationen von Git und Maven angehen.
Der aufmerksame Leser wird sich vielleicht 2 Dinge fragen:
- Git ist ein verteiltes Versionskontrollsystem, warum und wozu also ein zentrales Repository?
- Wozu ein Maven Repository Manager?
In einem Unternehmen macht es durchaus Sinn ein Bare Repository einzurichten, da es die gemeinsame Entwicklung, das Release Management und auch Deployments vereinfachen kann.
Ein Grund für ein Bare Repository in einem Projekt an dem man alleine arbeitet ist die Backup Funktionalität eines Git Bare Repository.
In diesem Blog Post (englisch) wird kurz und knapp erklärt, welche Möglichkeiten man mit Git repositories hat.
Ein Maven Repository Manager wie z.B. Apache Archiva oder Sonatype Nexus, hat ebenso Vorteile ab einer Teamstärke die größer ist als zwei, aber vorallem im Unternehmen hat man eine saubere Repository Verwaltung, die als Proxy für remote repositories dient.
Daher ist der erste Teil dieses Artikels eher für IT Verantwortliche relevant, z.B. Qualitäts- oder Releasemanager. Der zweite Teil ist auf jeden Fall für alle Entwickler wichtig, die mit Git oder Maven arbeiten wollen.
Motivation
Mir geht es in diesem Artikel darum zu zeigen, wie eine Infrastruktur im Unternehmensumfeld aufgesetzt werden kann, die sich an den Bedürfnissen eines Entwickler Teams orientiert und auch in Prozesse wie Qualitätssicherung und Releasemanagement sauber integrieren lässt.
Es gibt neben Git natürlich noch einige andere Versionskontrollsysteme, die auch in der Praxis etabliert sind. Ich persönlich habe ca. 3 Jahre mit Subversion gearbeitet, einige Monate mit dem alten CVS und zu Beginn meiner IT Karriere sogar ganz ohne Versionskontrolle, und das leider in einem Team aus 2-3 Entwicklern.
Mittlerweile bin ich aber voll von Git überzeugt und kann auch niemandem mehr empfehlen ein anderes VCS einzusetzen. Ich hatte durchaus meine Bedenken und Schwierigkeiten, während der Übergangsphase von SVN auf Git. Ich hatte mich gefragt, warum Git in der Presse und in den Foren so populär geworden ist. Die Vergleiche mit SVN waren stets unglaublich gut für Git ausgefallen und als ich das Video von Git Erfinder Linus Torvalds gesehen hatte, musste ich Git unbedingt testen. Es gibt letztlich nur 2 Kleinigkeiten, die ich etwas umständlich bei Git finde, und zwar rekursive Pulls, wenn man mit Submodules arbeitet, sowie die fehlende Unterstützung von Authorisierung und Authentifikation out-of-the-box, wie es z.B. SVN hat.
Im Bereich Build Management gibt es ebenfalls einige mehr Tools als Ant oder Maven. Meine Kenntnisse mit Apache Ant sind nicht besonders tief, aber ich würde auch hier niemandem mehr empfehlen mit Ant ein Projekt zu starten. Es ist zwar eine gewisse Einarbeitungszeit in Maven notwendig, und der Prozess des Umdenkens ist ähnlich aufwendig, wie von SVN zu Git, aber man wird sich schon nach kurzer Zeit fragen, warum man nicht schon früher umgestiegen ist. Zumindest ging das mir so vor nicht allzu langer Zeit.
Ein wichtiger Punkt ist natürlich die Rolle beider Technologien im Enterprise Umfeld. Ich kenne kaum ein Unternehmen, dass nicht den Umstieg auf beide Tools vollziehen möchte oder bereits getan hat. Auch in Stellenausschreibungen haben Git und Maven seit einiger Zeit schon mehr Präsenz als SVN und Ant.
Voraussetzungen
Wir benötigen diverse Software, die wir entsprechend konfigurieren werden, um eine professionelle Infrastruktur mit Eclipse, Git und Maven aufzubauen.Server-Side (Linux Debian)
- Virtuelle Maschine mit Linux Debian
- APT - Paketmanager unter Debian Systemen zur einfachen Installation von Software unter Linux
Workstation PC (Windows 7)
- JDK
- Apache Maven 3
- Eclipse
- m2eclipse
- EGit
- PuTTY (optional, man kann auch das Terminal von VirtualBox nutzen, was allerdings nicht so komfortabel ist wie PuTTY)
- WinSCP (optional, WinSCP ist ein SSH File Browser)
Umsetzung
Kurzübersicht aller Schritte
- WinSCP herunterladen, installieren und konfigurieren (~15min)
- Server-Side Installationen durchführen, z.B. JDK und Apache Archiva (~30min)
- JDK für Windows herunterladen und installieren (ohne Anleitung)
- Apache Maven herunterladen und installieren (~15min)
- Eclipse herunterladen und installieren (ohne Anleitung)
- Eclipse Plugins EGit) und m2eclipse installieren (~15min)
1. WinSCP mit PuTTY
Bitte WinSCP herunterladen und installieren. Wer PuTTY aus WinSCP heraus öffnen möchte muss auch PuTTY herunterladen. Eine Installation ist bei PuTTY nicht notwendig, einfach die EXE in einem Verzeichnis ablegen.Starten Sie WinSCP und geben Sie die Verbindungsdaten des Servers ein:

Klicken Sie auf Save... um die Verbindung für den späteren Schnellzugriff zu speichern oder klicken Sie direkt auf Login. Anschließend sind Sie im Benutzerverzeichnis von root:

Jetzt konfigurieren wir PuTTY, um per Button direkt eine Konsole öffnen zu können. Der PuTTY Button ist der 8. von links (2 Monitore).
Klicken Sie im Menü auf "Options -> Preferences..." oder per Shortcut Strg + Alt + P und anschließend auf Applications:

Tragen Sie den Pfad zu Ihrer PuTTY EXE ein und bestätigen OK.
Wer möchte kann noch einen Texteditor konfigurieren mit dem Dateien aus WinSCP geöffnet werden:

2. Server-Side Installationen
Installation JDK 7
Unter Linux Debian ist der APT Paketmanager Standard. Leider gibt zum Zeitpunkt als ich diesen Artikel geschrieben habe keine Möglichkeit mehr die Java SE Version 7 per apt zu installieren, da Oracle die Lizenz aufgekündigt hatte.
Mit folgendem Kommando kann man unter Linux Debian die verfügbaren Java Versionen wechseln:
update-alternatives --config javaMit diesem Kommando kann man die aktuell aktive Java Version ermitteln:
java -versionBeginnen wir mit dem Herunterladen des JDK Installationspakets. Sie finden die passende Variante (32bit, 64bit) auf der Oracle Website.
Sie müssen das Paket leider ohne wget herunterladen, da Oracle eine Bestätigung per Radiobutton vor dem Download benötigt. Nach dem Download können Sie mit WinSCP die Datei auf die virtuelle Maschine laden und zwar nach /usr/src.
Entpacken Sie das Java Paket:
tar -xzvf jdk-7u11-linux-i586.tar.gzAnschließend verschieben Sie das entpackte Verzeichnis:
mkdir /usr/lib/jvm mv /usr/src/jdk1.7.0_11 /usr/lib/jvm/ ln -s /usr/lib/jvm/jdk1.7.0_11/ /usr/lib/jvm/java-7-oracleDas Erzeugen des symbolischen Links vereinfacht die Verwlatung der Java Installationen und spätere Updates auf neue Versionen.
Anschließend aktivieren wir die Java Version auf dem System:
update-alternatives --install "/usr/bin/java" "java" "/usr/lib/jvm/java-7-oracle/bin/java" 1Mit java -version sollten Sie nun die neue Java Version angezeigt bekommen:
java version "1.7.0_11" Java(TM) SE Runtime Environment (build 1.7.0_11-b21) Java HotSpot(TM) Client VM (build 23.6-b04, mixed mode)Einige Java Anwendungen setzen die Umgebungsvariable JAVA_HOME voraus. Diese setzen wir mit folgenden Befehlen:
nano /etc/profileGeben Sie die folgenden 2 Zeilen an das Ende der Datei ein:
JAVA_HOME="/usr/lib/jvm/java-7-oracle" export JAVA_HOMESpeichern Sie die Datei mit Strg+O und verlassen Sie den nano Editor mit Strg+X. Anschließend aktivieren Sie noch diese Änderung und testen die Ausgabe der Umgebungsvariable:
source /etc/profile echo $JAVA_HOME
Installation Apache Archiva
Hinweis vom 06.06.2013:Mittlerweile gibt es Archiva in Version 1.4 und diese Anleitung basiert noch auf der Version 1.3.5. Die Schritte haben sich nicht geändert, aber die Screenshots sind nun veraltet, da Archiva auch ein etwas anderes Design bekommen hat.
Laden Sie das Installationspaket von Apache Archiva herunter, diesmal mit wget:
cd /usr/src
wget http://mirror.derwebwolf.net/apache/archiva/[VERSION]/binaries/apache-archiva-[VERSION]-bin.tar.gzEntpacken Sie die Datei:
tar -xvzf apache-archiva-[VERSION]-bin.tar.gzÄndern Sie am besten den Standard Port :8080 auf :8098 oder einen anderen Port Ihrer Wahl. Diese Konfiguration können Sie in der Datei /usr/src/apache-archiva-[VERSION]/conf/jetty.xml in folgender Zeile vornehmen:
<Set name="port"><SystemProperty name="jetty.port" default="8098"/></Set>Starten Sie Apache Archiva:
/usr/src/apache-archiva-[VERSION]/bin/archiva startNach ein paar Sekunden ist Archiva gestartet und Sie erreichen Archiva unter folgender URL:


Sie haben damit nun einen Repository Manager für Maven Projekte. Diesen richten wir noch als Proxy repository auf dem Workstation PC ein, um eine einheitliche Verwaltung der Artefakte über alle Entwickler Workstation PCs zu gewährleisten, z.B. muss ein Artefakt nur einmal aus dem Internet heruntergeladen werden, da Apache Archiva das zentrale Repository für alle Workstation PCs ist.
Hier ein Vergleich von Repository Management Tools.
4. Installation Apache Maven 3
Laden Sie ein Binary Paket von der offiziellen Apache Maven Homepage herunter. Entpacken Sie das Paket in ein Verzeichnis Ihrer Wahl - eine Installation ist unter Windows nicht notwendig. Das Ergebnis sieht so aus:



Für Maven 3 muss man wie auch für Maven 2 eine Umgebungsvariable MAVEN_HOME (kann auch umbenannt werden) einrichten:



Nun sollten Sie noch testen, ob die Maven Konfiguration auf Ihrem System erkannt wird. Dazu öffnen Sie die Kommandozeile von Windows und geben mvn -v ein. Dann sollte die Ausgabe ungefähr so aussehen:

Jetzt haben Sie Maven 3 korrekt "installiert".
Falls Sie bereits Apache Archiva aufgesetzt haben können Sie es jetzt in der Maven Konfiguration als zentrales/globales Repository eintragen. Dazu öffnen Sie die Datei .m2/settings.xml in Ihrem Benutzerverzeichnis, z.B. unter

Konfigurieren Sie Ihren Archiva Server als Mirror in der settings.xml, z.B.
Wir werden dieses Repository später in Eclipse unter Global Repositories wiedersehen. Doch erstmal müssen wir die dafür notwendigen Eclipse Plugins installieren.internal-blogger * Internal Apache Archiva http://192.168.0.111:8098/archiva/repository/internal
6. Installation EGit und m2eclipse
Hier die URLs zur Installation in Eclipse über Help -> Install new software...
http://download.eclipse.org/egit/updates
http://download.eclipse.org/technology/m2e/releases
Wählen Sie folgende Komponenten aus:


Klicken Sie sich durch und bestätigen Sie die Lizenzbestimmungen. Sie werden nach der ersten Installation von Eclipse gefragt, ob Sie den notwendigen Neustart durchführen möchten. Antworten Sie mit Nein und installieren das zweite Plugin. Danach können Sie Eclipse neustarten lassen.
Nach dem Neustart haben Sie neue Perspektiven und Sichten in Eclipse zur Verfügung. Hier die neuen Sichte, die Sie über Window -> Show View - Other... erreichen:

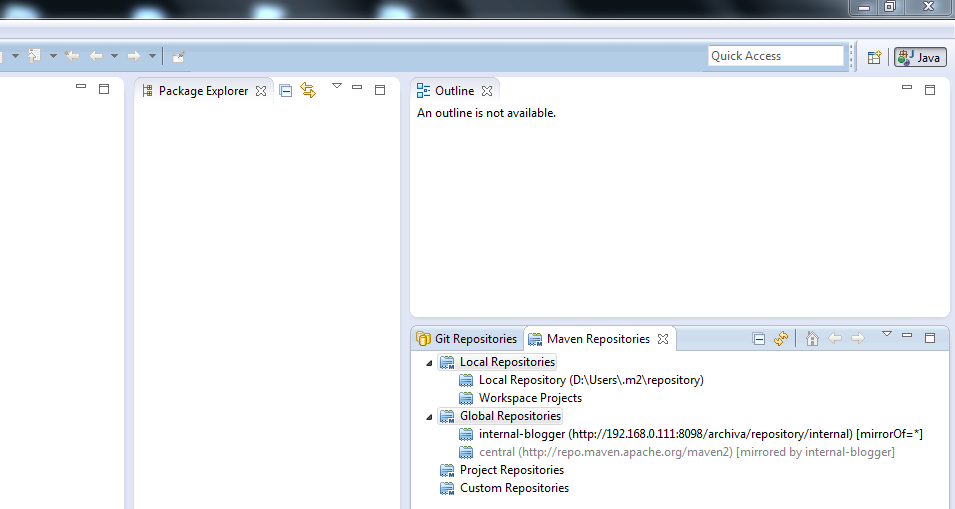
Ebenso sieht man unter Global Repositories einen internal Eintrag, der das Apache Archiva Repository konfiguriert hat. Diese Einstellung kommt durch die mirror Konfiguration in der settings.xml unter .m2/settings.xml, die Sie am Ende der Maven Installation evtl. durchgeführt haben.
Übrigens...
da wir Git auf der Workstation nur über die IDE (hier Eclipse) anwenden und keinen Bedarf an der Benutzung über die Konsole haben, müssen wir Git nicht direkt installieren. Das Eclipse Plugin reicht in diesem Fall völlig aus.
Zusammenfassung
Sie haben nun eine Worksation für die Entwicklung von Java Projekten mit Git, Maven und Eclipse. Die Plugins EGit und m2eclipse sind aktuell die besten Plugins für Git und Maven unter Eclipse.
Auf der Server-Side läuft ein Apache Archiva als Proxy Repository. Dieses ermöglicht eine professionellere Organisation von abhängigen Bibliotheken in der Java Entwicklung. Insbesondere für IT Verantwortliche aus den Bereichen Qualitätssicherung, Releasemanagement und Deployment ist das eine hilfreiche Lösung.
Weitere Schritte
In den nächsten Artikeln werde ich auf dieser Basis zeigen, wie man Apache Archiva weiter konfigurieren kann, wie man ein Git Bare Repository auf der Server-Side erstellt und anschließend auf der Workstation klont, und ich werde ein erstes Java Projekt mit Maven aufsetzen, welches natürlich unter Versionskontrolle von Git steht.
Git hat von Haus aus keine Zugriffskontrolle. In einem Unternehmen kann es aber notwendig werden bestimmten Entwicklern, z.B. Freelancer, eingeschränkten Zugriff auf bestimmte Projekte zu geben. Für diesen Fall gibt es Gitosis oder das aktuellere Gitolite, aber auch Gerrit.














